

Let's dig into the fascinating, sometimes chaotic, but often rewarding world of free, open-source, and less-common AI tools for music creation.
Forget the glossy ads for a moment; the real cutting edge often bubbles up from research labs, passionate open-source communities on GitHub, and experimental platforms like Hugging Face.
This is where you find the truly unique sonic possibilities, often for free, if you're willing to explore.
Unconventional AI Plugins & Standalone Processors
Finding fully-featured, free AI creative plugins (like synths or complex effects) is still less common than finding AI utility tools. However, some gems exist, and many powerful AI processes are available as standalone applications or scripts rather than traditional VSTs.
AI-Powered Noise Reduction & Restoration:
Before you even get creative, cleaning up audio is crucial. While many commercial tools exist, the open-source world offers potent alternatives. Bertom Denoiser Classic is a fantastic free plugin that leverages AI for surprisingly transparent noise reduction, excellent for tidying up field recordings or sampled vinyl crackle without overly degrading the source. Furthermore, the core RNNoise model is an open-source project focused on noise suppression, and while direct plugins are rare, you might find implementations within other open-source audio software or experimental builds. Even the venerable open-source editor Audacity now includes built-in AI noise reduction features, making basic cleanup accessible to everyone.
Bertom Audio Denoiser Classic:
Before you even get creative, cleaning up audio is crucial. While many commercial tools exist, the open-source world offers potent alternatives. Bertom Denoiser Classic is a fantastic free plugin that leverages AI for surprisingly transparent noise reduction, excellent for tidying up field recordings or sampled vinyl crackle without overly degrading the source. Furthermore, the core RNNoise model is an open-source project focused on noise suppression, and while direct plugins are rare, you might find implementations within other open-source audio software or experimental builds. Even the venerable open-source editor Audacity now includes built-in AI noise reduction features, making basic cleanup accessible to everyone.
Bertom Audio
Denoiser Classic

RNNoise Project:
RNNoise is a noise suppression library based on a recurrent neural network.
GitHub
RNNoise Project
Experimental Sound Synthesis & Effects (Beyond VSTs):
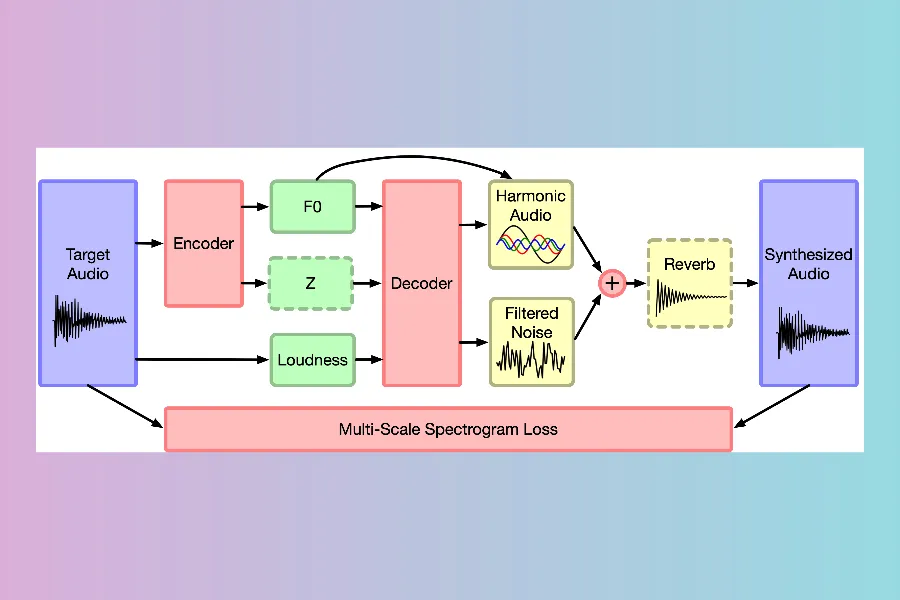
Truly novel AI sound generation within a free plugin format is still developing. However, research projects often release their code. Technologies like DDSP (Differentiable Digital Signal Processing) from Google's Magenta team allow AI models to learn to control synthesizers to replicate sounds. While often requiring Python knowledge to use directly, exploring DDSP resources on GitHub or Magenta's site can lead to unique sound design experiments. Similarly, models like RAVE (Realtime Audio Variational autoEncoder) offer high-fidelity neural audio synthesis, sometimes demonstrated in web demos or available as open-source code for those willing to dive in. The key here is often exploring GitHub repositories tagged with "AI," "audio synthesis," or specific model names.
AI MIDI Generation: The Infinite Idea Machine
AI truly shines when breaking creative blocks for melodies, harmonies, and rhythms. Several free and open-source options provide endless streams of MIDI inspiration, often with surprisingly musical results.
Accessible Web Tools: For instant gratification without any installation, MIDIGEN is a standout. This simple web app lets you pick scales, keys, tempos, and complexity to generate royalty-free MIDI melodies, chords, and arpeggios you can download and drag directly into your DAW. It's an excellent bookmark for those moments you're staring at a blank piano roll.
MIDIGEN:

MIDIGEN is an AI-powered MIDI music generator designed to revolutionize the way you create music. Whether you're a seasoned composer, a budding musician, or someone who loves experimenting with sound, MIDIGEN is your go-to tool for crafting royalty-free MIDI chords and melodies with ease and precision.
Features:
- Free, web-based, no sign-up
- Generates Melodies, Arpeggios, Chords
- Customizable parameters (Key, Scale, Tempo, etc.)
- Royalty-free MIDI download
MIDIGEN
melody-generator
Magenta Project & Tools:
Exploring Research Frameworks: Google's Magenta project offers more than just research papers; it includes tools you can often run locally or find hosted online. Magenta Studio, though potentially needing updates or community maintenance, included standalone applications like Continue (extends MIDI clips), Generate (creates new patterns), and Groove (humanizes drum patterns). Even if not actively developed by Google, the underlying models and code are often available on GitHub. Similarly, OpenAI's MuseNet, known for generating longer, coherent musical pieces, doesn't have an official interface but can often be accessed through third-party web GUIs like MuseTree, built by the community to interact with the model. Searching platforms like Hugging Face for "MIDI generation" models can also uncover newer projects.
Magenta
GitHub
Magenta
Musenet & musetree:
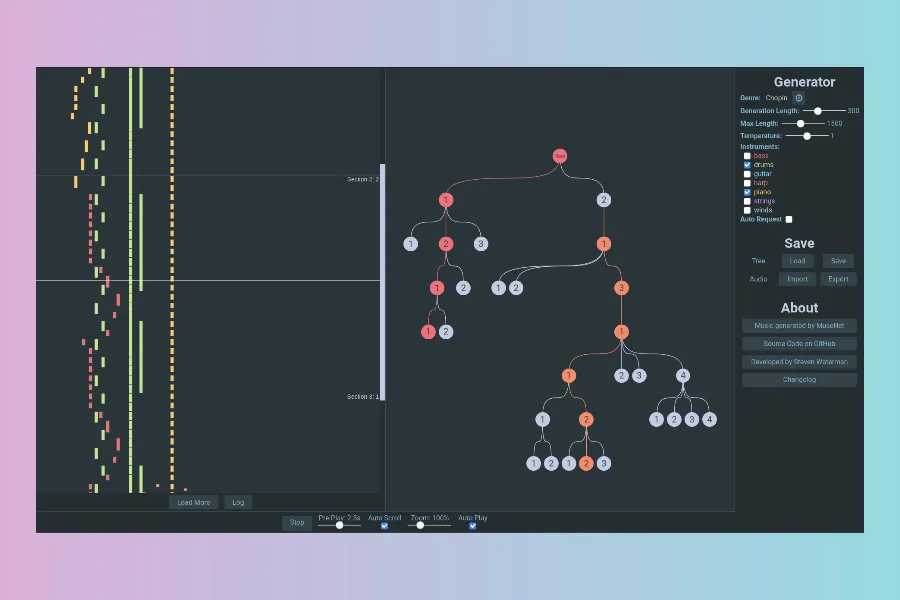
MuseTree is a custom front-end for OpenAi's MuseNet, the AI music generator. The official app is a toy designed to show off the research. In contrast, MuseTree is designed for real music production, and has been built from the ground-up with that in mind.
GitHub
MuseTree
OpenAI
MuseNet
AI Audio & Music Generation: Sound From Thin Air
Generating actual audio from text prompts or style examples is one of the most exciting AI frontiers. While professional platforms exist, numerous free and open-source options allow experimentation.
Free Text-to-Music Web Demos: Several sites offer quick, no-strings-attached text-to-audio generation. MusicHero.ai, AIMusic.so, and AIMusicGen.ai are examples where you can type a prompt like "ambient techno loop with phasing pads 125 bpm" and get a short audio clip. These are perfect for generating unique textures, one-shot samples, or rhythmic loops to sample and mangle further in your DAW. The quality can be unpredictable, but the surprise element is part of the fun.
MusicHero:

Create your own music easily with MusicHero.ai's free AI music generator from text. No sign-up required!
AIMusicGen.ai:
Transform your ideas into songs instantly with our AI music generator - no sign-up required. Create AI generated music with your custom text or lyrics.
Riffusion:
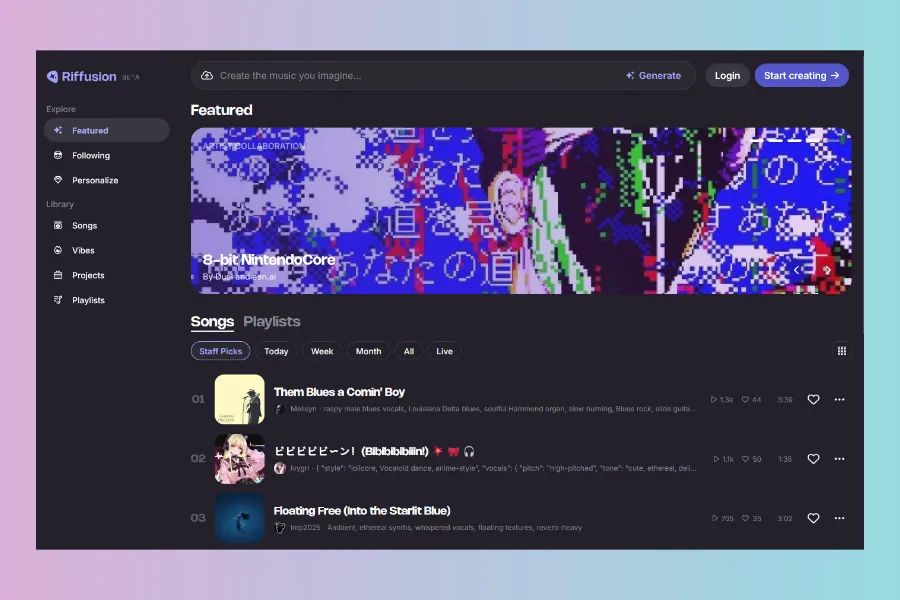
Riffusion is a neural network, designed by Seth Forsgren and Hayk Martiros, that generates music using images of sound rather than audio
Cutting-Edge Open Source Models:
For maximum control and quality (at the cost of complexity), dive into the open-source models themselves. Meta AI's MusicGen is a powerful model capable of generating high-fidelity music from text prompts, often available to try via Hugging Face Spaces (web demos hosted by the AI community) or runnable locally if you have the technical setup (Python, potentially a GPU). AudioLDM is another potent text-to-audio model. Exploring Hugging Face's "Text-to-Audio" or "Music Generation" sections reveals a constantly evolving landscape of these foundational models. Riffusion also remains interesting for its unique approach of using Stable Diffusion (an image model) on audio spectrograms.
These tools range from simple loop generators to complex models requiring coding knowledge. The free web tools are great for quick inspiration, while diving into Hugging Face/GitHub unlocks the raw power of state-of-the-art AI audio synthesis.
The AI Utility Belt: Specialized Free & Open Source Tools
Beyond direct creation, AI excels at highly specific, often laborious tasks. This is where free and open-source tools truly shine, often outperforming commercial counterparts due to focused development.
Stem Separation Supremacy:
Need to isolate vocals, drums, or bass from a full mix? Forget paying per track. Ultimate Vocal Remover (UVR) is a phenomenal free, open-source desktop application that provides a user-friendly interface for state-of-the-art AI stem separation models like Demucs (from Meta AI) and Spleeter (from Deezer), plus several others. You can choose different models optimized for various tasks (like isolating vocals vs. instruments vs. just drums/bass) and fine-tune parameters, often achieving cleaner separations than simplistic online tools. This is indispensable for remixing, sampling, and analysis.
Ultimate Vocal Remover (UVR):
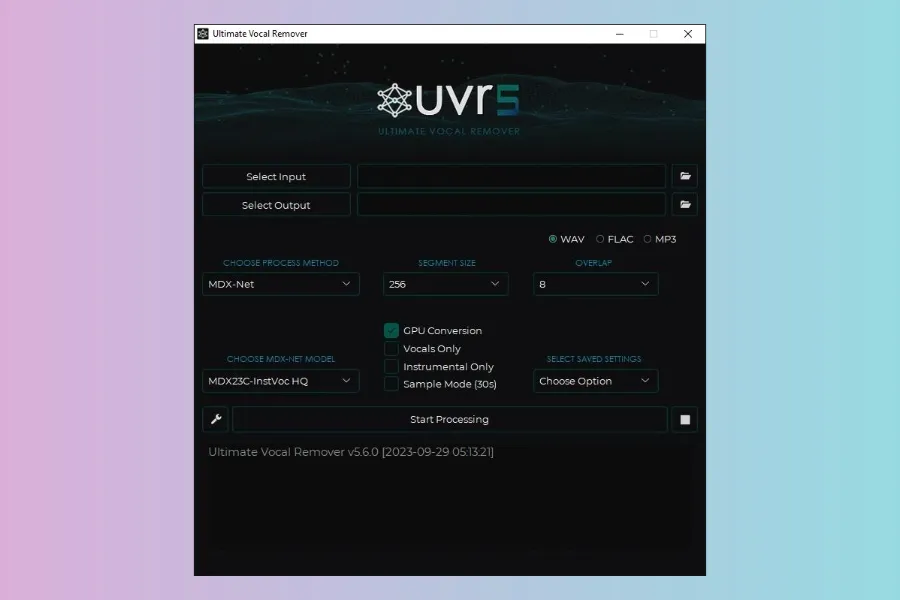
A Free, Open Source Desktop App - HIGHLY Recommended
The best vocal remover application on the internet, and it's totally free and open source! Available on Windows, Mac, & Linux
Demucs / Spleeter:
Demucs is a state-of-the-art music source separation model, currently capable of separating drums, bass, and vocals from the rest of the accompaniment. Demucs is based on a U-Net convolutional architecture inspired by Wave-U-Net. The v4 version features Hybrid Transformer Demucs, a hybrid spectrogram/waveform separation model using Transformers. It is based on Hybrid Demucs (also provided in this repo), with the innermost layers replaced by a cross-domain Transformer Encoder. This Transformer uses self-attention within each domain, and cross-attention across domains. The model achieves a SDR of 9.00 dB on the MUSDB HQ test set. Moreover, when using sparse attention kernels to extend its receptive field and per source fine-tuning, we achieve state-of-the-art 9.20 dB of SDR.
Spleeter is Deezer source separation library with pretrained models written in Python and uses Tensorflow. It makes it easy to train source separation model (assuming you have a dataset of isolated sources), and provides already trained state of the art model for performing various flavour of separation :
- Vocals (singing voice) / accompaniment separation (2 stems)
- Vocals / drums / bass / other separation (4 stems)
- Vocals / drums / bass / piano / other separation (5 stems)
Vocal Synthesis & Transformation:
Creating or modifying vocals with AI is rapidly evolving. Synthesizer V Studio Basic offers a free, non-commercial version of a powerful AI singing synthesizer, letting you type lyrics and create surprisingly realistic vocal lines with adjustable parameters. For voice cloning and transformation, Kits AI provides a user-friendly web platform with a generous free tier to experiment with training AI voice models or using pre-existing ones. Delving deeper, open-source projects like So-VITS-SVC (and its variants) allow high-quality voice conversion (making one voice sound like another). These often require significant technical effort, using platforms like Google Colab and resources found on GitHub, but offer unparalleled control for the dedicated user.
Synthesizer V Studio:

Unfortunately there is no free version avalable anymore.
Synthesizer V Studio Pro: $89.00
Synthesizer V Studio 2 Pro: $99.00
Kits AI:
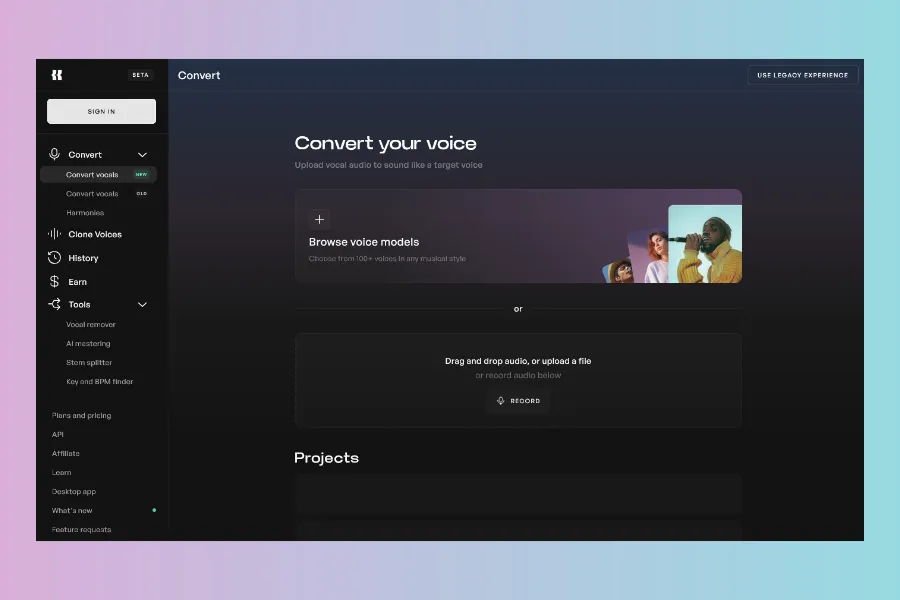
AI Voice Models on Kits.AI — Clone voices, sing like anyone, play any instrument, isolate vocals. 100% Royalty Free. Kits Ai - Streamline your workflow with studio-quality AI audio tools. Try Free. Responsible Dataset. Precision Vocal Cloning. Empowering Creators. 5,000K+ Creators.
So-VITS-SVC & forks:

In the field of Singing Voice Conversion, there is not only one project, SoVitsSvc, but also many other projects, which will not be listed here. The project was officially discontinued for maintenance and Archived. However, there are still other enthusiasts who have created their own branches and continue to maintain the SoVitsSvc project (still unrelated to SvcDevelopTeam and the repository maintainers) and have made some big changes to it for you to find out for yourself.
Intelligent Sample Management & Generation:
While AI sample browsers (like Atlas, XO) tend to be commercial, Samplebrain is a unique open-source project conceived by Aphex Twin and developed by Dave Griffiths. It doesn't just organize samples; it chops and recombines sounds from your library based on similarity metrics, creating novel sound collages and textures from your existing collection. It's a truly experimental approach to sample manipulation. For generating new sounds, AI Sound Effect Generators are emerging. While dedicated free tools are sparse, searching Hugging Face Spaces for "sound effect generation" or "text-to-sound" will often reveal demos based on models trained specifically for SFX.
Samplebrain:
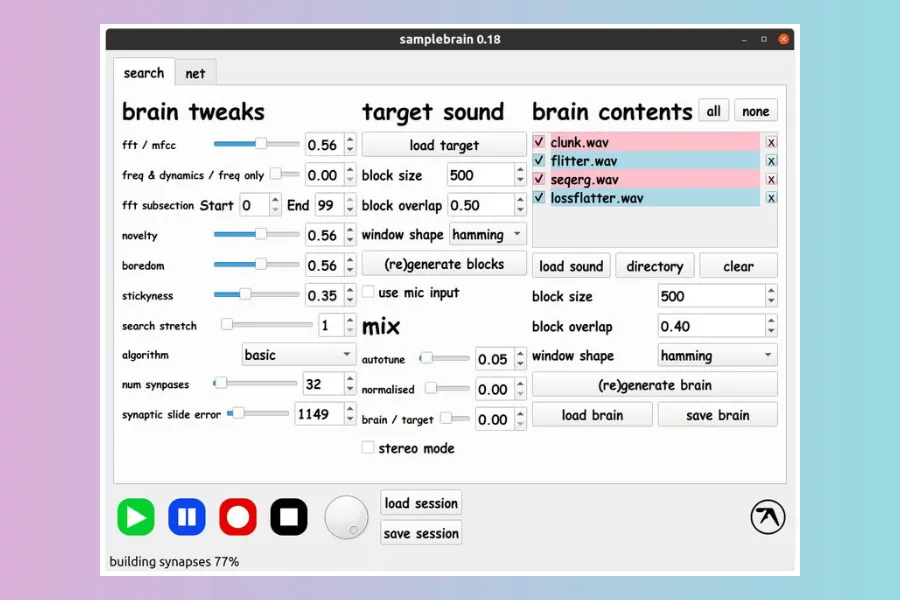
A custom sample mashing app designed with Aphex Twin.
Samplebrain chops samples up into a 'brain' of interconnected small sections called blocks which are connected into a network by similarity. It processes a target sample, chopping it up into blocks in the same way, and tries to match each block with one in it's brain to play in realtime.
This allows you to interpret a sound with a different one. As we worked on it (during 2015 and 2016) we gradually added more and more tweakable parameters until it became slightly out of control.
Samplebrain is free software
Embrace the Open Source Frontier
The landscape of free and open-source AI music tools is dynamic and exciting. It requires a bit more exploration—navigating GitHub, trying out Hugging Face demos, perhaps even running a Python script via Google Colab. However, the rewards are immense: access to powerful, cutting-edge technology without the price tag, unique tools that foster experimentation, and a connection to a vibrant community of developers and researchers pushing the boundaries of sonic creation. These tools aren't just utilities; they are invitations to explore uncharted musical territories. Dive in, experiment, and see what strange and wonderful sounds you can conjure with your new AI collaborators.
HIT OR SHIT Indicator
💩
Indication by Noizefield
Average Indication by Readers
🚀
What do you think?
Hit or Shit? Please rate from 1 (💩) to 10 (🚀)
✅ You already voted. Thanks!
Check these out!
